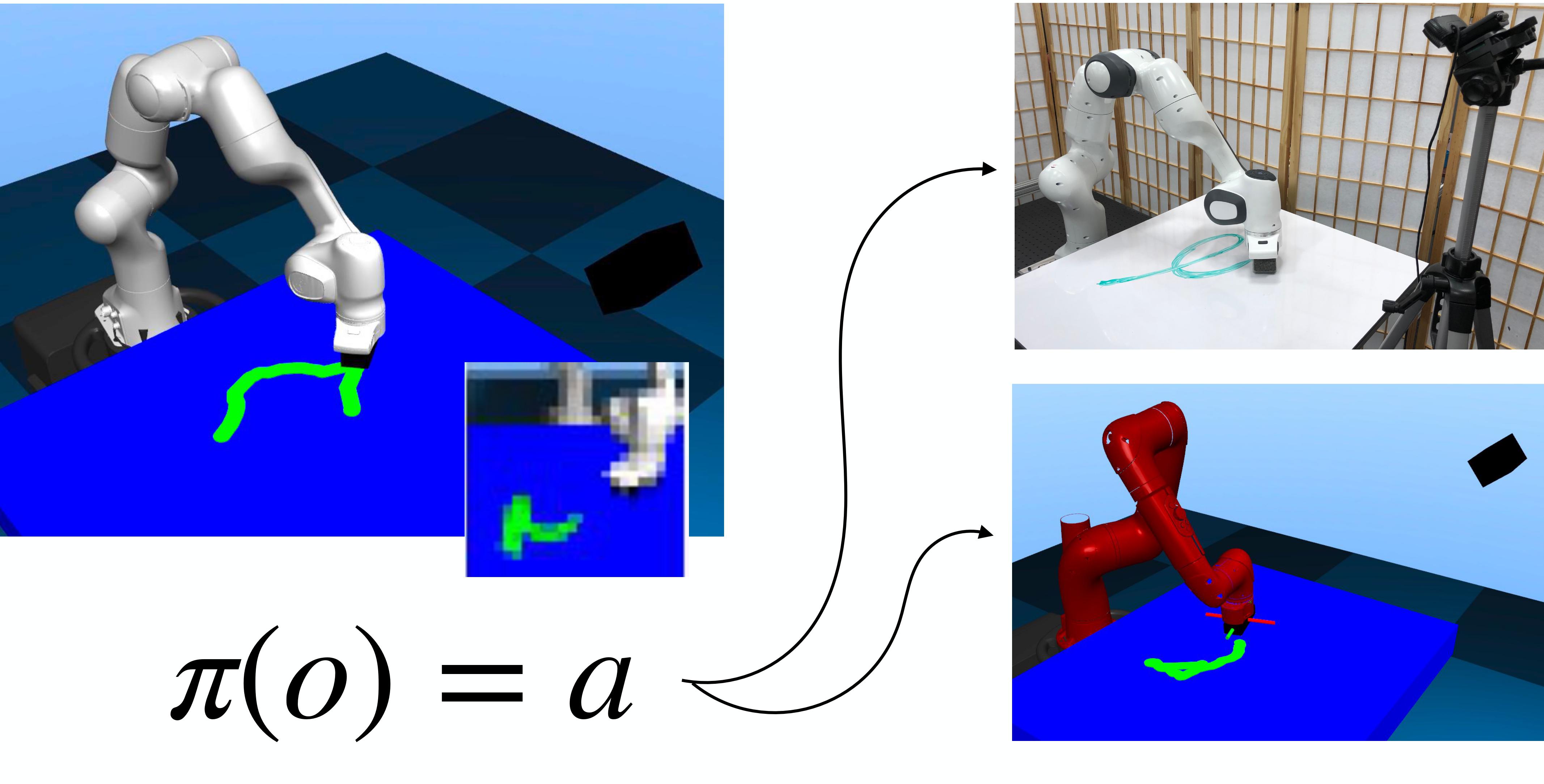
Variable Impedance Control in End-Effector Space:
An Action Space for Reinforcement Learning in Contact-Rich Tasks
Roberto Martín-Martín, Michelle A. Lee, Rachel Gardner, Silvio Savarese, Jeannette Bohg, Animesh Garg

Paper: Arxiv 1710.01813, presented at IROS19
@inproceedings{martin2019iros,
title={Variable Impedance Control in End-Effector Space. An Action Space for Reinforcement Learning in Contact Rich Tasks},
author={Mart\'in-Mart\'in, Roberto and Lee, Michelle and Gardner, Rachel and Savarese, Silvio and Bohg, Jeannette and Garg, Animesh},
booktitle={Proceedings of the International Conference of Intelligent Robots and Systems (IROS)},
year={2019}
}
Code: Robosuite, branch vices_iros19
Different tasks are more naturally defined in different action spaces. As a roboticist, imaging you want to code a robot to perform different activities such as imitating a dance, cleaning a window, or hanging a jacket. For each of these tasks you would probably choose a different action space ranging from joint space positions and velocities, to end-effector poses or some kind of force-control. Trying to imitate a full-body dance commanding end-effector poses, or wipe a delicate surface commanding joint positions is unnecessarily hard. However, when it comes to robot learning (and specifically, reinforcement learning, RL), very few studies investigate the role of the action space in the performance of the learning algorithms.
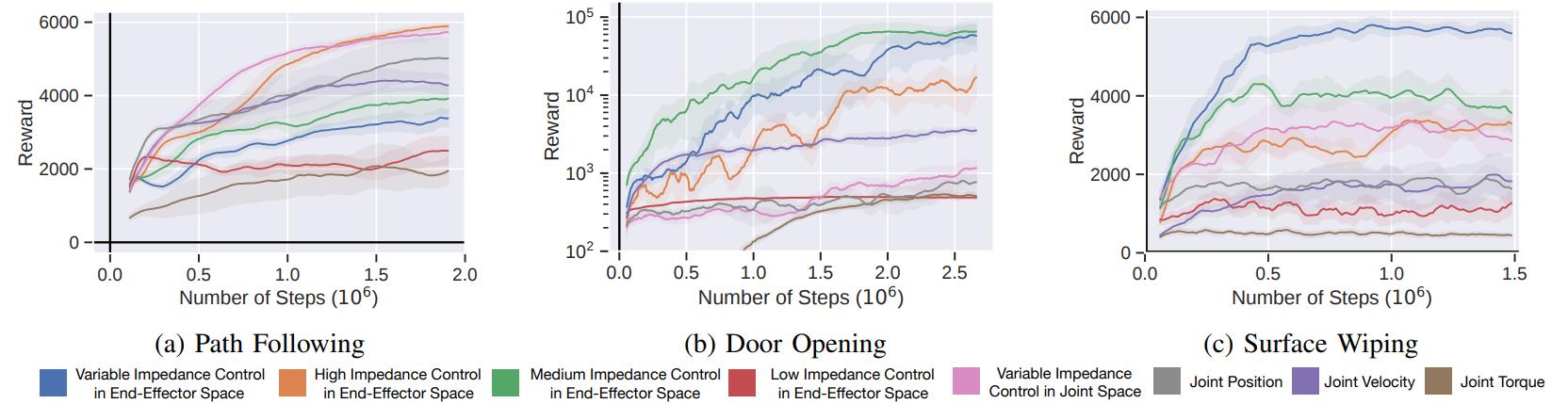
In this work, we investigate how the choice of an action space impacts in the performance of deep RL algorithms. We study three tasks with complementary properties that represent important domains in robotics: 1) free space motion with a path following task, 2) manipulation of constrained mechanisms with a door opening task, and 3) contact-rich manipulation with a surface wiping task. The tasks are shown in the figure below this paragraph. On these tasks, we evaluate how RL is affected by action spaces by comparing eight action spaces: joint positions, joint velocities, joint torques, variable joint impedance, and impedance control in end-effector space with high, medium, low, or variable (policy-controlled) values. This last action space (Variable Impedance Control in End-Effector Space, VICES) has not traditionally be used as space to learn RL policies; we observed that this space lead to some benefits for deep RL, especially for contact-rich tasks.

The plots below show the sample effiency (reward as function of simulation samples) for the three different tasks and the eight action spaces (five random seeds each). We observe that for a task without contact, like the path following task, controlling the pose of the end-effect reaches the higher levels of reward. Controlling the impedance in end-effector space doesn’t seem to provide much benefit, although controlling impedance for each joint achieves good results. However, as the level of contact increases, the benefits of actively controlling the impedance in end-effector space become clearer.
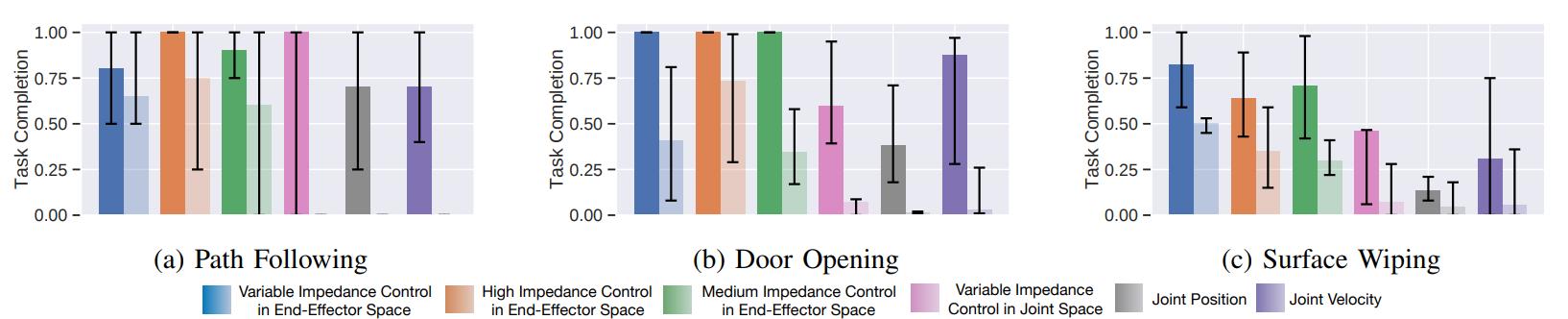
We also evaluate if we can transfer directly policies we train with one type of robot to another type of robot without any retraining. To do this, we train in simulation using a Franka Panda robot and test on a Rethink Robotics Sawyer platform. The results are shown in the figures below this paragraph. Some action spaces are not depicted because they didn’t reach a minimum level of success with the original embodiment. We observe that the policies trained in end-effector space transfer better to other embodiments. This lesson may be familiar to practitioners with background on robot control, since it is a benefit of using the dynamically decoupled Operational Space formalism. We also test if the best policy trained in simulation to wipe the table transfers to the real Panda robot. Simplifying the visual input, we observe that the control policy transfer well to the real world and the robot successfully wipes the table (shown at the end of the video).
Conclusion: In this study we show that different action spaces have a fundamental role in the performance of deep RL algorithms. While commonly ignored, or just briefly mentioned in RL studies, we advocate for a more thoughtful and reasoned exploration of the best action spaces when testing RL algorithms. We also proposed and evaluated variable impedance control in end-effector space (VICES) as action space for RL and observed beneficial properties when used to learn contact-rich tasks. As next steps we will investigate if the most beneficial action space can be autonomously found by the agent.
Video:

Acknowledgment
This work has been partially supported by JD.com American Technologies Corporation (“JD”) under the SAIL-JD AI Research Initiative. This article solely reflects the opinions and conclusions of its authors and not JD or any entity associated with JD.com.